Experimental Results
Evaluated on HaluEval (10K QA + 10K Summarisation samples) with a 70/30 dev/test split.
Summary
| Metric | v2 (standard) | v2 (realistic) |
|---|---|---|
| Combined F1 (best C3) | 0.6998 | 0.6558 |
| QA F1 | 0.770 (C2 = C3) | — |
| QA Over-flagging | 11.2% (C3 Tiered) | — |
| Summarisation | F1 ≈ 0.663 (fixed from 99%+ FPR in v1) | — |
| Realistic FPR (C2 → C3 Sqrt) | — | 100% → 44.9% |
| C3 vs C2 significant? | No (p = 1.0) | Yes (p = 0.000014) |
Combined Test Set — Standard (n = 6,000)
| Condition | F1 | Precision | Recall | Over-flagging |
|---|---|---|---|---|
| C1 (RAG-only) | 0.000 | 0.000 | 0.000 | 0.0% |
| C2 (Static CONLI) | 0.6988 | 0.6014 | 0.8338 | 55.3% |
| C3 Tiered | 0.6998 | 0.6010 | 0.8374 | 55.7% |
| C3 Sqrt | 0.6998 | 0.6008 | 0.8378 | 55.7% |
| C3 Sigmoid | 0.6992 | 0.6005 | 0.8368 | 55.7% |
QA Test Set (n = 2,959)
| Condition | F1 | Precision | Recall | FPR |
|---|---|---|---|---|
| C2 (Static) | 0.7702 | 0.8418 | 0.7098 | 13.6% |
| C3 Tiered | 0.7679 | 0.8629 | 0.6917 | 11.2% |
| C3 Sqrt | 0.7618 | 0.8776 | 0.6729 | 9.5% |
| C3 Sigmoid | 0.7687 | 0.8221 | 0.7218 | 15.9% |
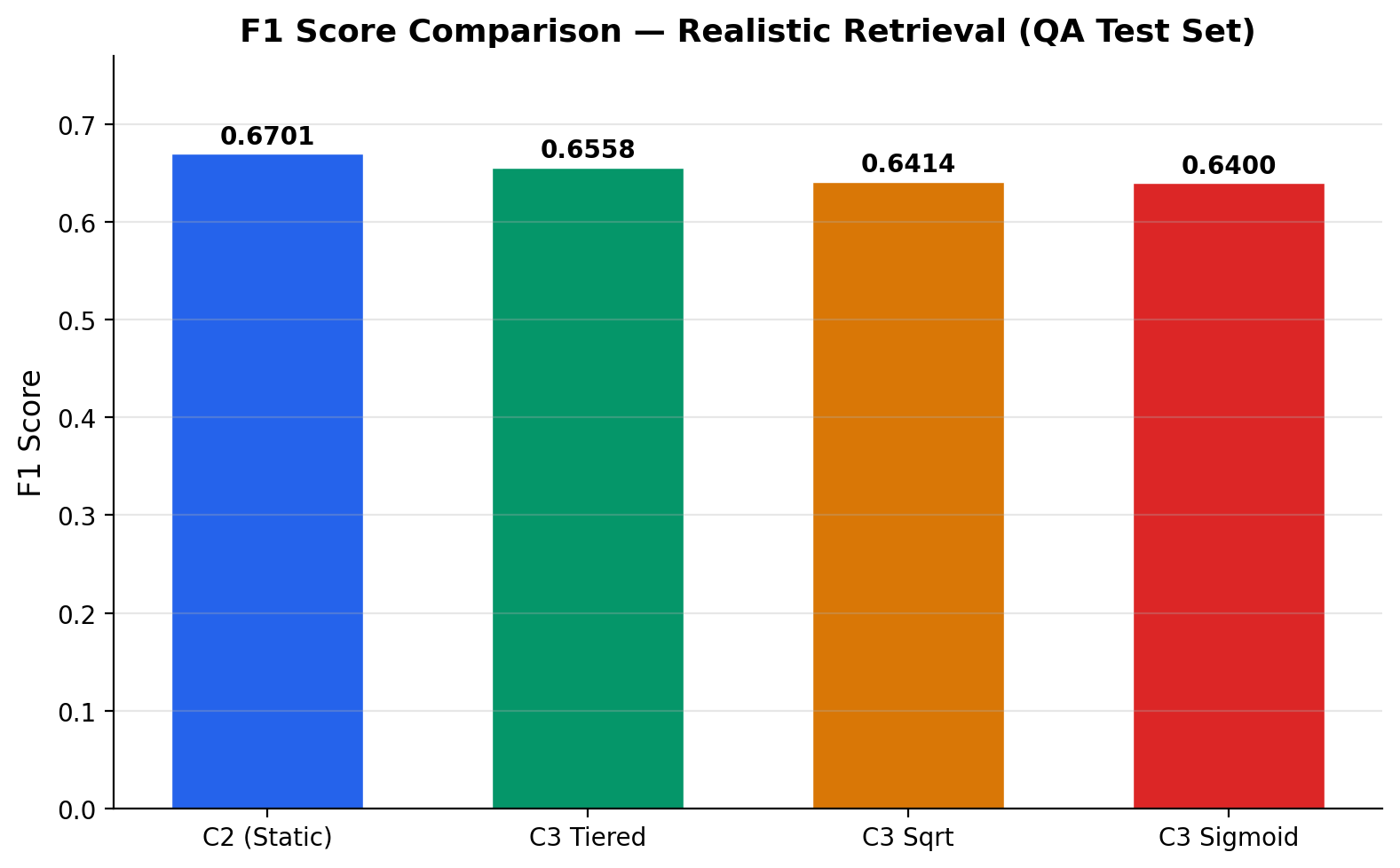
Realistic Retrieval — Shared Index (n = 5,918)
This experiment uses a shared FAISS index across all QA samples (realistic RAG conditions) instead of per-sample ground-truth retrieval.
| Condition | F1 | Precision | Recall | FPR |
|---|---|---|---|---|
| C2 (Static) | 0.6701 | 0.5041 | 0.9993 | 100.0% |
| C3 Tiered | 0.6558 | 0.5236 | 0.8773 | 81.2% |
| C3 Sqrt | 0.6414 | 0.6067 | 0.6803 | 44.9% |
| C3 Sigmoid | 0.6400 | 0.5604 | 0.7460 | 59.5% |
Statistical Significance (McNemar's Test)
| Split | Statistic | p-value | Significant? |
|---|---|---|---|
| Combined (standard) | 0.000 | 1.0 | No |
| QA | 0.544 | 0.461 | No |
| Summarisation | 0.056 | 0.814 | No |
| Realistic | 18.884 | 0.000014 | Yes |
Key Finding
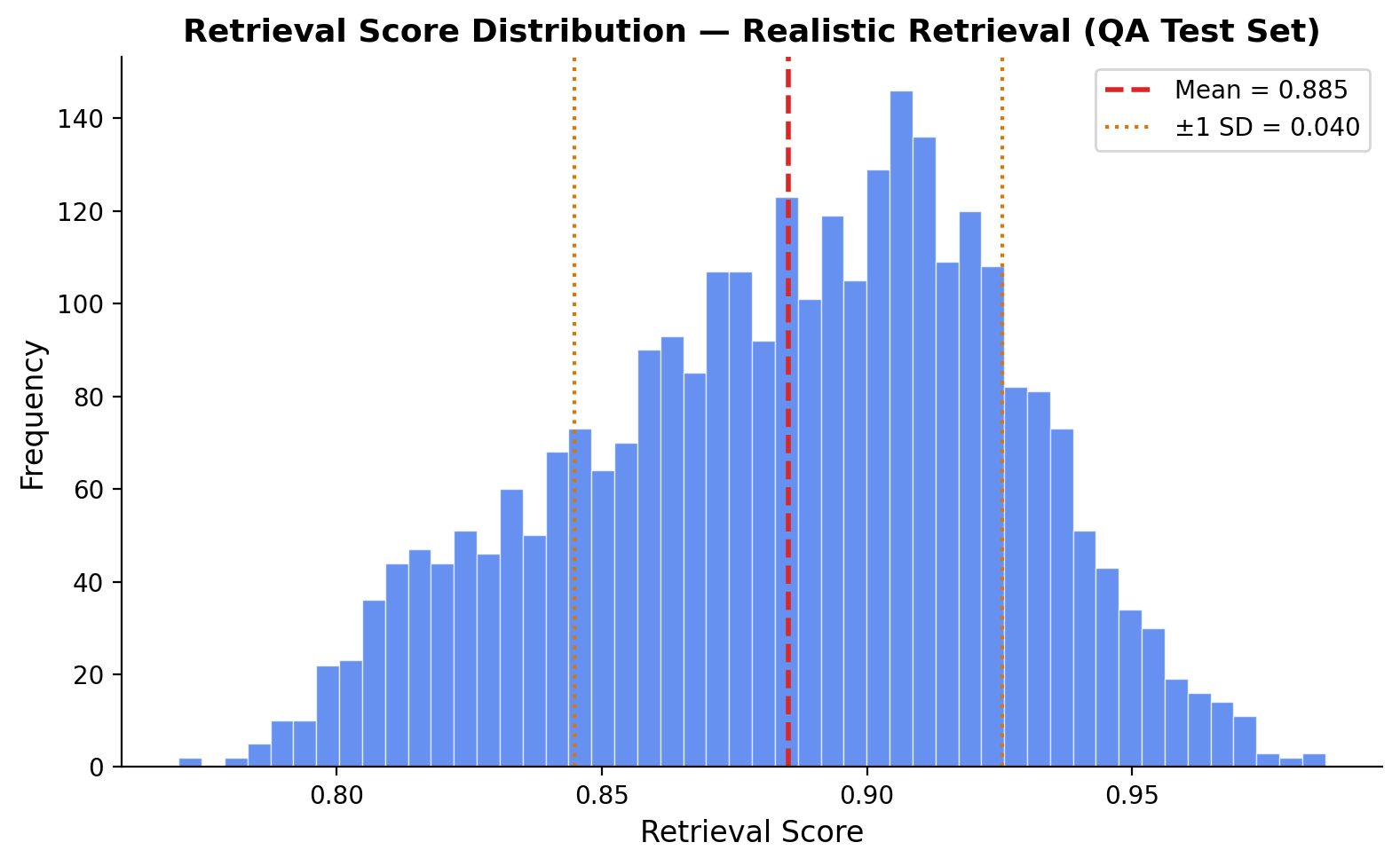
On HaluEval's standard per-sample retrieval, C3 and C2 converge to the same operating point — retrieval scores cluster too tightly (QA std = 0.075) for adaptive thresholds to differentiate. Under realistic shared-index retrieval, the difference is significant: C2 flags 100% of correct responses while C3 Sqrt reduces over-flagging to 44.9%.
The primary contribution is v2 engineering: sliding-window NLI fixes summarisation (99% FPR → functional), claim decomposition catches partial hallucinations, and BGE embeddings improve retrieval fidelity.
Running Experiments
# Full v2 pipeline (recommended)
python run_v2.py # ~4h GPU, ~24h CPU
# Step by step
python calibrate.py --split dev
python evaluate.py --precompute --split dev --version v2
python evaluate.py --precompute --split test --version v2
python tune.py --split dev --version v2
python evaluate.py --condition C3 --split test --version v2
python analyze.py --split test --version v2